We Ran 9 Experiments in One Session and Kept Zero. Here's What We Actually Learned.

We spent an entire research session trying to make Kettio’s ad scoring system better. We tested 9 different modifications, ran them against two independent human benchmark datasets, and kept exactly zero.
That sounds like a failure. It’s actually one of the most productive research sessions we’ve had.
The Setup
Kettio scores ad creatives using a method called Semantic Similarity Rating (SSR). Instead of asking an AI to rate an ad on a 1–5 scale (which produces useless middle-of-the-road answers), we build a synthetic persona of your target audience, show them the ad, and ask: “You’re scrolling through your feed. You see this. What do you do next and why?”
The model writes a free-text reaction. We embed that reaction into a vector space and compare it against calibrated reference statements at each score level. The semantic distance between the reaction and these reference points produces a probability distribution, which becomes the final score.
This approach correlates with real human ad judgments at ρ=0.69 on one benchmark (500 web ads rated by crowdsourced annotators) and ρ=0.62 on another (1,000 ad images from an eye-tracking study with 57 participants). Those are strong correlations for a zero-shot system with no training data.
The question was: can we do better?
6 Prompt Experiments, 6 Reverts
We started where most ML engineers start: the prompt. The system prompt tells the model who it is and how to behave. The persona description tells it about the audience. The goal question tells it what to evaluate. Each of these is a lever you can pull.
We pulled them all:
- Normalized scores instead of natural language. Instead of telling the model the persona is “skeptical of exaggerated claims,” we tried “adSkepticism: 0.75.” A recent paper showed this reduces artificial persona repetition. Result: purchase-intent correlation dropped 5%.
- Narrative-style persona descriptions. Instead of comma-separated traits, we wove them into prose: “This person is aged 25–34, lower-middle income. They are moderately price-sensitive and skeptical of advertising claims.” Result: trust correlation improved 6%, but purchase-intent dropped 5%. Net negative.
- Internal reasoning directive. We told the model to “briefly consider how this person would actually think and feel” before reacting. Result: both benchmarks dropped 11–15%. Worst single-benchmark drop of the session.
- Simulation framing. Changed “You are a real person scrolling” to “You are accurately simulating a real person scrolling.” Result: both benchmarks dropped 7–16%. The model performs better when it IS the person, not when it’s told it’s pretending to be one.
- Goal context in system prompt. Pre-primed the model with “focus on whether you would purchase this” before showing the ad. Result: catastrophic — 33% drop. The model over-anchored on the goal verb and stopped reacting naturally.
- Enriched behavioral phrases. Made persona trait descriptions more detailed: “skeptical of claims — looks for fine print, questions too-good-to-be-true offers.” Result: flat to slightly negative. The extra detail didn’t help.
Six experiments, six reverts. Every direction we pushed — richer descriptions, different framing, more instruction, less instruction — either hurt or was flat.
The Pattern Nobody Talks About
Here’s what the failed experiments taught us:
The system prompt is a local optimum. After months of iteration, the prompt layer is highly tuned. Small changes in any direction make it worse. This isn’t surprising for a well-optimized system, but it means further gains aren’t coming from prompt engineering.
Telling the model to think harder makes it worse. The “internal reasoning” and “simulation framing” experiments both degraded performance. This aligns with something we’d discovered earlier: disabling the model’s extended thinking mode actually improves scoring accuracy. The model’s first instinct as a persona is better than its considered judgment.
The goal should come as a question after seeing the content, not as an instruction before. Pre-priming the goal caused the biggest single drop we’ve ever seen. The model needs to react to the ad naturally, then be asked about a specific dimension. Putting the goal first turns the reaction into a forced evaluation rather than an authentic response.
But the most important finding came after we gave up on prompts.
Try it free — rank your ads in 30 seconds
No credit card. No media spend.
Looking Under the Hood: Anchor Geometry
If the prompts are optimized, what’s left? We turned to the scoring layer — the reference statements (we call them “anchors”) that the model’s reaction is compared against.
Our system uses calibrated anchor phrases at each score level. For purchase intent, score 1 might be “I would definitely not buy this” and score 5 might be “I would definitely buy this.” The reaction text gets embedded and compared to these anchor embeddings via cosine similarity.
We visualized all 195 anchor embeddings projected into 2D using t-SNE. What we found was striking:
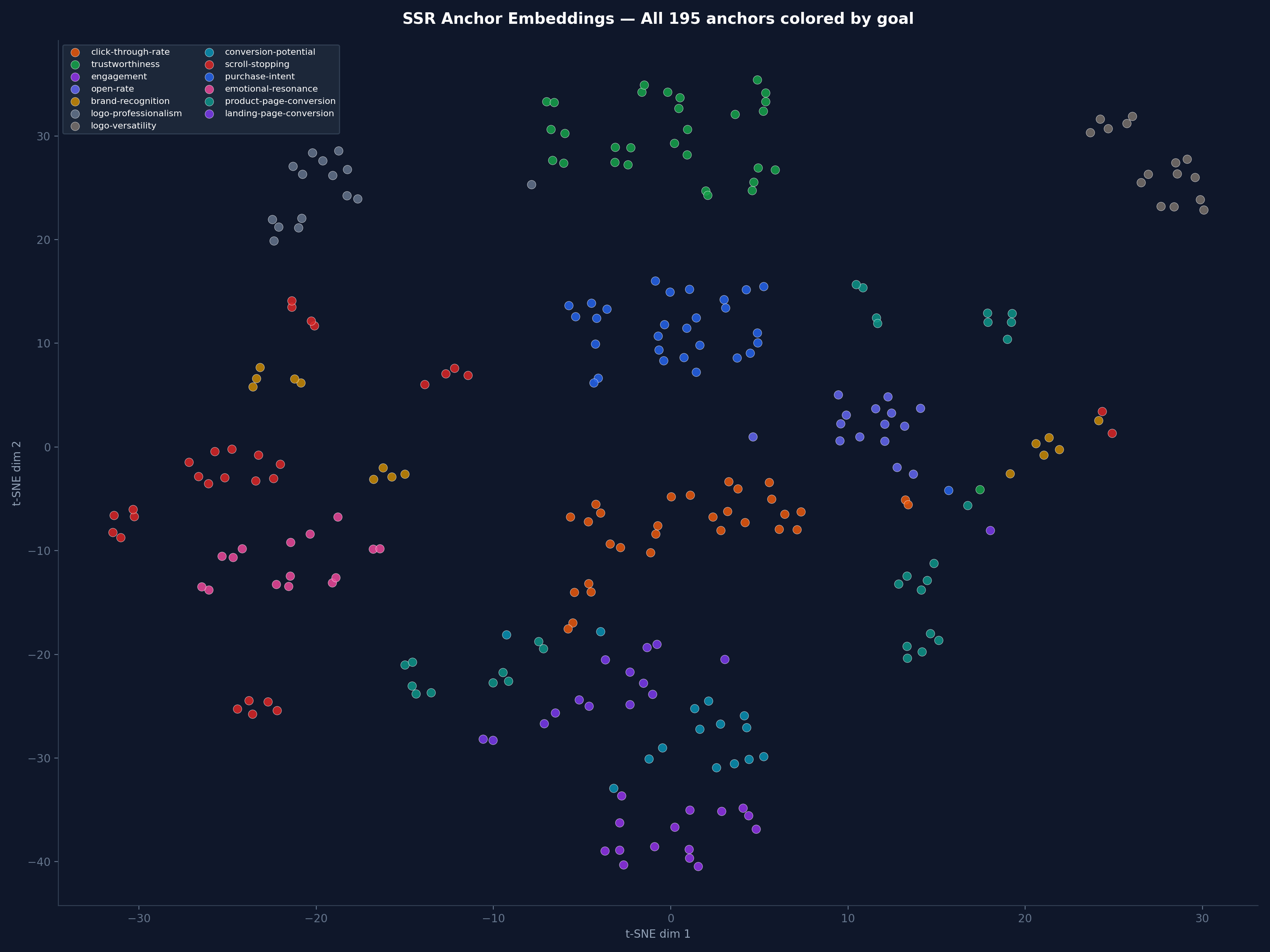
Each color is a different evaluation goal (purchase intent, trustworthiness, click-through rate, etc.). The anchors form loose clusters, but with massive overlap between goals. Some goal pairs share so much embedding space that their anchors are nearly interchangeable.
More concerning was the within-goal structure:
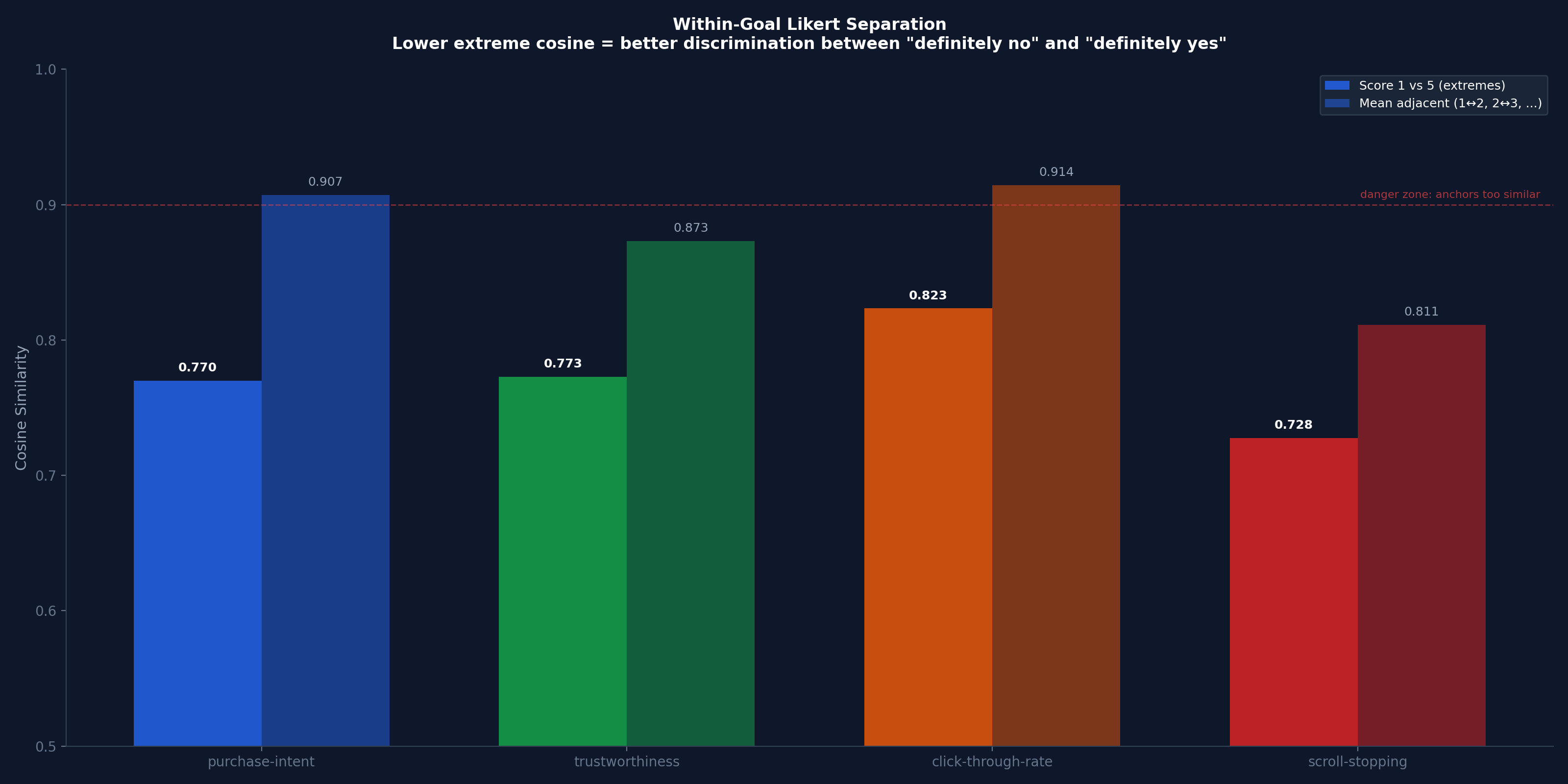
This chart shows how far apart the “definitely no” and “definitely yes” anchors are for each goal. Lower cosine similarity = more room for the scoring function to discriminate. Click-through rate’s extreme anchors have 0.82 cosine similarity — they’re almost the same point in embedding space. Adjacent score levels (score 2 vs 3, for example) are at 0.91 — functionally identical.
Why? Because “I would definitely click on this” and “I would definitely not click on this” are the same sentence with a negation. Embedding models capture topic more than stance. Both sentences are about clicking, so they’re close together.
The Experiment That Changed Our Understanding
This led to a hypothesis: what if we replaced the attitude-scale anchors (“I would/would not buy”) with behavioral-description anchors that describe different actions at each score level?
Instead of:
- Score 1: “I would definitely not buy this”
- Score 5: “I would definitely buy this”
We tested:
- Score 1: A description of scrolling past without registering the ad
- Score 5: A description of immediately wanting to look up the product
The embedding space separation was 3.7x wider. The effective dynamic range went from 0.20 to 0.75. On paper, this should be a massive improvement.
Here’s what actually happened on the benchmarks:
| Anchor Style | Survey Benchmark (ρ) | Eye-tracking Benchmark (ρ) |
|---|---|---|
| Attitude scale (current) | 0.70 | 0.23 |
| Behavioral descriptions | 0.33 | 0.64 |
The behavioral anchors tripled the eye-tracking benchmark while halving the survey benchmark. They didn’t fail — they’re measuring something fundamentally different.
Two Benchmarks, Two Truths
This is the insight that made the whole session worthwhile.
Attitude anchors (“I would/would not buy”) correlate with stated preferences — what people say they’d do in a survey context. This is what traditional consumer panels measure.
Behavioral anchors (“I scrolled past” vs “I’m opening a new tab to buy this”) correlate with subjective ad appeal — how much real people, sitting in a lab with eye trackers, actually like the ad.
These aren’t the same thing. An ad that survey respondents say they’d buy is not necessarily the ad that genuinely captures attention and desire. And vice versa.
We confirmed this by testing a hybrid (3 attitude sets + 3 behavioral sets averaged together). The survey benchmark still dropped 9%. The behavioral signal dilutes the attitude signal even in a 50/50 mix. They’re pulling in different directions.
What We Shipped: Nothing. What We Learned: Everything.
We didn’t change the production system. The current configuration — attitude-scale anchors with the existing prompt stack — achieves ρ=0.62–0.69 across two independent human benchmarks. That’s strong. It ranks ads correctly the majority of the time.
But we now understand the system at a level we didn’t before:
- The prompt layer is optimized. Further gains aren’t coming from prompt engineering. The system prompt, persona construction, and goal framing are well-tuned after months of iteration.
- The anchor geometry defines what you’re measuring. Attitude anchors measure stated preference. Behavioral anchors measure genuine appeal. They’re different instruments, not better or worse versions of the same one.
- Compressed embedding range isn’t a bug if the signal is accurate within that range. Our anchors are tightly clustered in embedding space, but the scoring function discriminates well enough. Like a precise thermometer with a narrow range — accuracy matters more than range.
- The real validation isn’t academic benchmarks — it’s campaign data. We have the infrastructure to A/B test SSR predictions against real campaign performance. That’s the ground truth that matters for our customers.
Sometimes the most valuable research session is the one that tells you to stop optimizing and start shipping.
What’s Next
We’re taking the behavioral anchor set and keeping it in our back pocket. For customers who care about predicting genuine ad appeal (think: scroll-stopping creative for social), behavioral scoring might be the right instrument. For customers who care about purchase intent prediction (think: product page optimization for ecommerce), the current attitude-based system is the right one.
Different questions need different measurement tools. The breakthrough wasn’t making one tool better — it was realizing we had the pieces for two.
If you’re spending on creative and want to know which ads will win before you spend, test them on Kettio.
Test your own ad creatives — free.
Drop one ad, pick an audience, and watch a synthetic version of your buyer react in 30 seconds. No media spend. No credit card.
Roast my ad free →